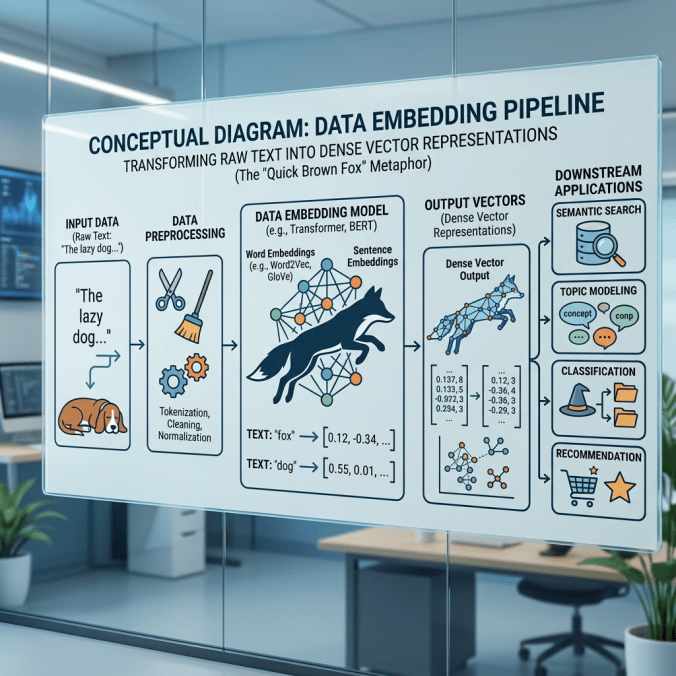
Nhúng (embedding) là bước chuyển đổi văn bản thành tri thức số hóa mà mạng nơ‑ron có thể xử lý. Nó vừa là dữ liệu đầu vào, vừa là tham số phải học. Trong quá trình huấn luyện, ma trận nhúng được cập nhật liên tục, khiến tri thức biểu diễn từ vựng ngày càng chính xác hơn.
Công việc nhúng có hai tác dụng:
- Chuyển đổi dữ liệu thưa thớt thành tri thức phân tán thống nhất
- Chuyển đổi kích thước đầu vào lớn, thay đổi như số lượng từ trong đoạn văn, thành kích thước nhỏ cố định của đầu vào thực của mạng.
Pipeline tổng quát
Văn bản mẫu (sample)
│
▼
Tách từ → Chỉ mục từ (word indices)
│
▼
Tra cứu ma trận nhúng (embedding matrix)
│
▼
Vector nhúng cho từng từ (sequence of vectors)
│
▼
Lấy trung bình theo sequence
│
▼
Vector đầu vào cố định cho mạng (embedding vector)
Chúng ta xem xét đoạn văn
“The quick brown fox jumps over the lazy dog”

Mỗi từ được biểu diễn bằng một vectơ trong không gian hai chiều. Trường hợp chung sẽ là n chiều. Những vectơ này sẽ được học và di chuyển trong không gian.
Các vectơ từ này thuộc về một ma trận nhúng với n cột và m hàng. Trong đó m = vocabulary_size là số lượng từ vựng. Mỗi mẫu là một đoạn văn thuộc về một lớp, các từ được ánh xạ thông qua từ điển đến vectơ của nó , từ đó truy cập bằng chỉ mục đến các vectơ hàng trong ma trận.
Một vectơ có cùng kích thước n lấy giá trị trung bình của các vectơ trong mẫu trở thành vectơ đầu vào thực của mạng.
Các phần tử của ma trận nhúng được tạo ra từ sự phân bố đồng đều trong phạm vi [-1.0, 1.0). Kích thước n còn được gọi là kích thước nhúng.
Vì vậy, thông qua một bước nhúng, chúng ta nhận được:
- Chuyển đổi câu mẫu thành các giá trị trong khoảng [-1.0, 1.0)
- Độ dài đoạn mẫu
sequencekhông cố định (lớn) trở thành độ dài cố định của vectơ nhúng (nhỏ).
Chúng ta xử lý mẫu theo lô, từng mẫu. Theo ngôn ngữ tensor, đầu ra ban đầu sẽ là một tensor 3D với vectơ kích thước (batch_size, sequence, embedding). Sau khi tính trung bình, chúng ta nhận được một tensor 2D với vectơ kích thước (batch_size, embedding), làm đầu vào chuẩn của mạng nơ‑ron.
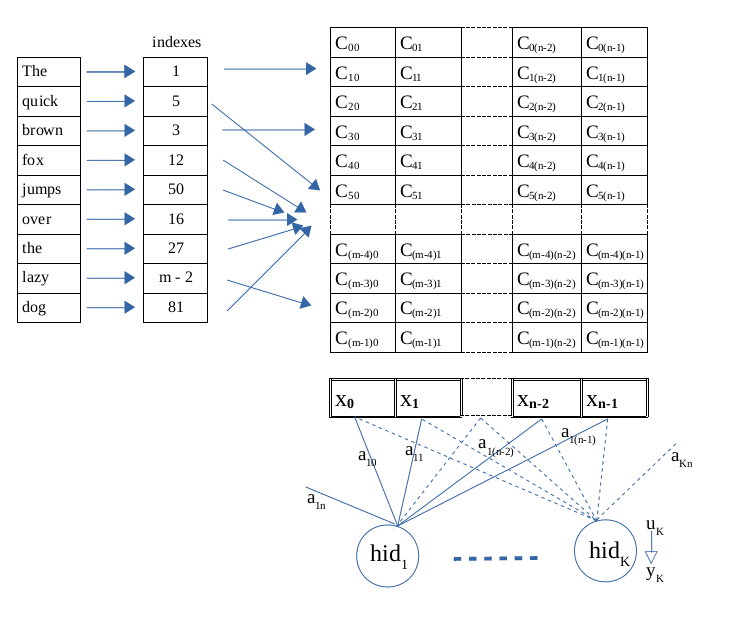
Nút ẩn hid1 có n+1 trọng số như bình thường, đó là a10, a11 … a1n. Mạng phải học thêm m × n trọng số hay tham số của ma trận nhúng.
Ví dụ, một mạng được thiết kế với 16 đầu vào, n = 16. Số từ vựng là m = vocabulary_size = 10000. Sau đó, số lượng tham số nhúng sẽ là 10000 × 16 = 160000.
Các đạo hàm riêng của hàm lỗi theo trọng số trên cùng một cột cho một mẫu là như nhau. Chúng ta có

Trong đó

Hàm chuyển kích hoạt nút ẩn. Đầu vào là uk, đầu ra là yk. Nếu chúng ta sử dụng hàm sigmoid thì

Vì vậy, công thức đạo hàm cuối cùng cho trọng số nhúng là

Trong đó ∂E / ∂yk là đạo hàm riêng của hàm lỗi theo đầu ra của nút ẩn kth như bài toán truyền thống.
